

High Availability is the terminology that ensures an operational continuity during any failure of primary system. Users want their application to be up and ready for use at all time. Availability defines the ability of the users to access the system, whether to submit new work, update or alter existing work, or collect the results of previous work and if they are not able to do so, these systems are supposed to be unavailable which in turn means downtime and productivity loss. The productivity loss means revenue loss. Generally, the term downtime is referred to the period when a system is unavailable. In order to make sure systems, services, applications are available 24X7, customer engage with solution providers to design the robust DR strategy and plan. Disaster Recovery (DR) is undertaking whereby an organization invests in computing hardware and software to be used when primary processing site becomes unavailable. In order to design the Disaster Recovery plan each business owner has to be a part as the decision of providing RPO (Recovery point objective) and RTO (Recovery time objective) depending upon the criticality of the application.
Following are the Traditional Approaches to Disaster Recovery:
Hot Site:
Hot Site means the duplication the whole environment from primary site to secondary site based on the DR strategy — an approach which, is expensive and requires a lot of investment and upkeep. Data duplication, keeping hot site servers and other components in sync is time consuming and expensive. A hot site consists of servers, storage systems, and network infrastructure comprises a logical duplication of the main production site. Servers and other components are maintained and kept at the same release and patch level as their primary production environment. Data at the primary site is usually replicated over a WAN link to the hot site. Failover may be automatic or manual, depending on the business requirements and available resources.
Cold Site:
The cold site approach proposes that, after a disaster occurs, the organization sends backup media to an empty facility, in hopes that the new computers they purchase arrive in time and can support their applications and data. Based on an organization’s recoverability needs, some applications may appropriately be recovered to cold sites. Another reason that organizations opt for cold sites is that they are effectively betting that a disaster is not going to occur, and thus investment is unnecessary.
Warm Site:
With a warm site approach, the organization essentially takes the midway between the expensive hot site and the empty cold site. Perhaps there are servers in the warm site, but they might not be current and similar to primary production site. It takes a lot longer (typically a few days or more) to recover an application to a warm site than a hot site, but it’s also a lot less expensive.
Disaster Recovery as A Service (DRaaS)
Disaster Recovery as a Service (DRaaS) is a cloud‐based service that makes it easy for organizations to set up disaster recovery sites. Like other “as a service” offerings, advanced software enables DRaaS to simplify the entire process for organizations of any size as well as the service providers that offer this service. DRaaS is important because it represents an innovative and less costly way to back up critical data and quickly recover critical systems after a disaster. DRaaS leverages cloud‐based resources/infrastructure/software that is far away expensive than on‐premise systems due to the ability to scale and shared cloud resources. To meet the growing demand for software resilience, DRaaS has brought simplification and reduced costs to organizations who are interested in implementing DR.
Disaster Recovery Planning
Disaster Recovery planning is one of the most important aspect of creating robust DR strategy. This starts with Business Impact Analysis (BIA). The objective of a BIA is to identify those business processes and their underlying IT systems that are most critical for the organization. You start by meeting business process owner and document them including the IT system, data stores and their dependencies on other system, if any. Once you have all processed documents, each business process owner knows the critically of the business and based on their need RPO (Recovery Point Objective) and RTO (Recovery Time Objective) and be defined. In order to achieve RPO and RTO, DR on cloud can be achieved quick and fast. There are various server providers who provide DRaaS now on their cloud.
DRaaS
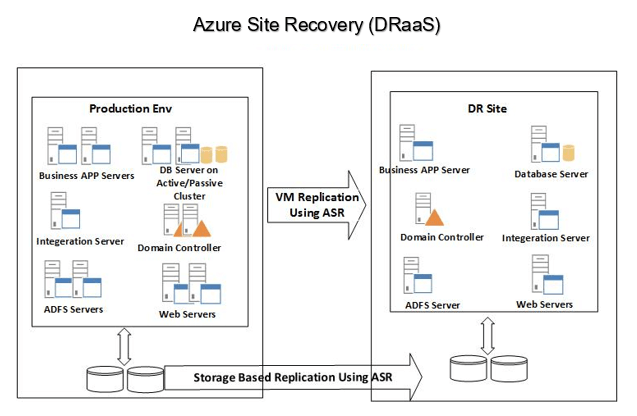
Disaster recovery as a service (DRaaS) is the replication and hosting of physical or virtual servers by a third party to provide failover in the event of any disaster (natural or man-made). There are various providers who offers these services. Microsoft offers similar service known as ASR (Azure Site Recovery). The services can be availed for Azure VM, on-premises VM or Physical Servers.
Azure Site Recovery (ASR)
Site Recovery services helps in achieving business continuity by replication VM or physical server from on-premises to Microsoft cloud infrastructure. In case of any disaster at the primary site, we can fail over to secondary location (Azure cloud) and keep our business application up and running. Once the primary site is restored, we can fail back to it.
Azure Site recovery can manage:
- Replication of VMs from one Azure location to another
- Replication of VM or physical servers from on-premises to Azure site
- Replicating VM from Azure Infrastructure to customer owned datacentre
Comments (0)